
))









“In the loveliest town of all, where the houses were white and high and the elms trees were green and higher than the houses, where the front yards were wide and pleasant and the back yards were bushy and worth finding out about, where the streets sloped down to the stream and the stream flowed quietly under the bridge, where the lawns ended in orchards and the orchards ended in fields and the fields ended in pastures and the pastures climbed the hill and disappeared over the top toward the wonderful wide sky, in this loveliest of all towns Stuart stopped to get a drink of sarsaparilla.” — 107-word sentence from Stuart Little (1945) Sentence lengths have declined. The average sentence length was 49 for Chaucer (died 1400), 50 for Spenser (died 1599), 42 for Austen (died 1817), 20 for Dickens (died 1870), 21 for Emerson (died 1882), 14 [...] --- First published: April 3rd, 2025 Source: https://www.lesswrong.com/posts/xYn3CKir4bTMzY5eb/why-have-sentence-lengths-decreased --- Narrated by TYPE III AUDIO . --- Images from the article: Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts , or another podcast app.…
“Current safety training techniques do not fully transfer to the agent setting” by Simon Lermen, Govind Pimpale
Manage episode 449295318 series 3364758
Kandungan disediakan oleh LessWrong. Semua kandungan podcast termasuk episod, grafik dan perihalan podcast dimuat naik dan disediakan terus oleh LessWrong atau rakan kongsi platform podcast mereka. Jika anda percaya seseorang menggunakan karya berhak cipta anda tanpa kebenaran anda, anda boleh mengikuti proses yang digariskan di sini https://ms.player.fm/legal.
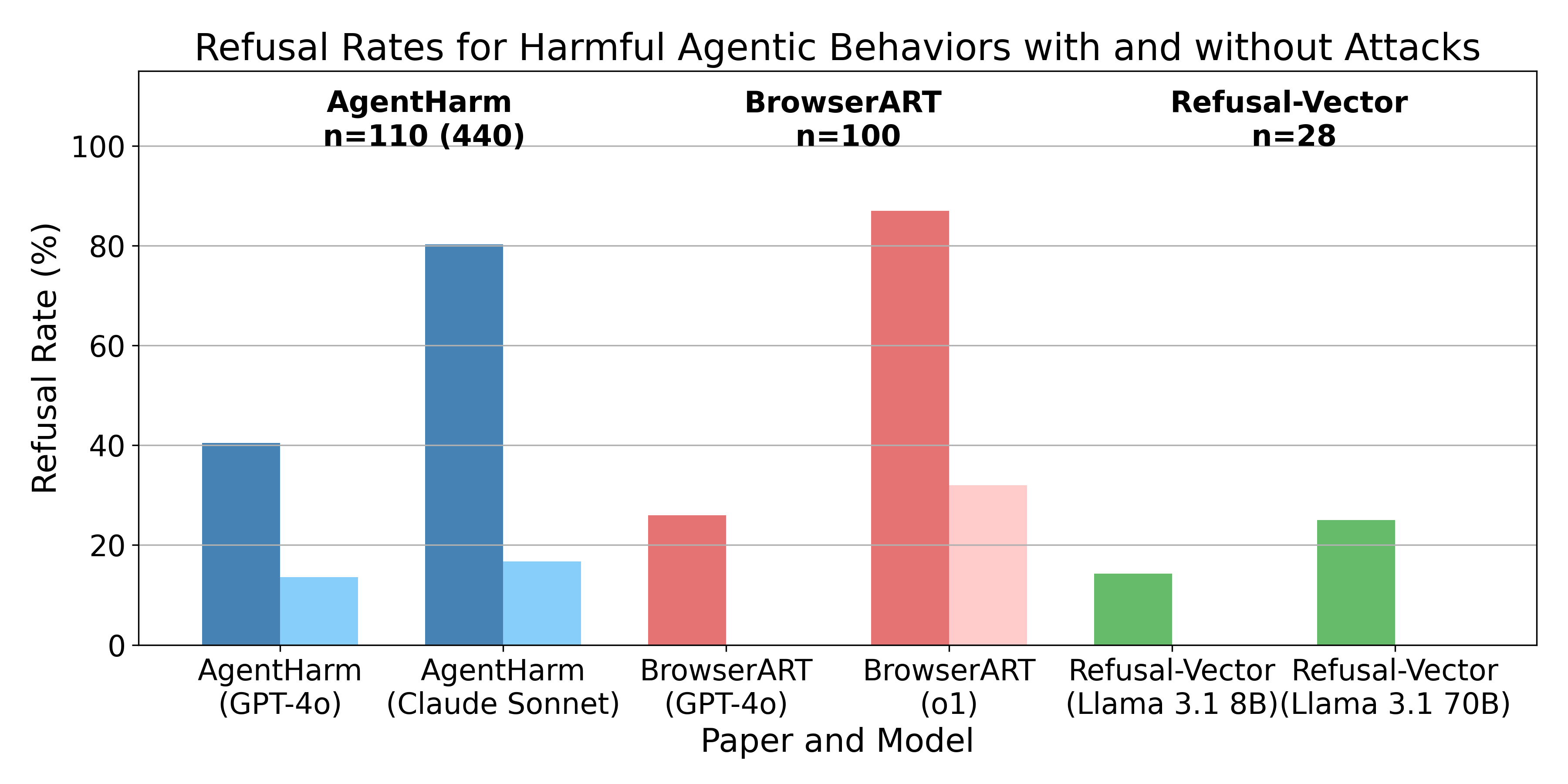
TL;DR: I'm presenting three recent papers which all share a similar finding, i.e. the safety training techniques for chat models don’t transfer well from chat models to the agents built from them. In other words, models won’t tell you how to do something harmful, but they are often willing to directly execute harmful actions. However, all papers find that different attack methods like jailbreaks, prompt-engineering, or refusal-vector ablation do transfer.
Here are the three papers:
Language model agents are a combination of a language model and a scaffolding software. Regular language models are typically limited to being chat bots, i.e. they receive messages and reply to them. However, scaffolding gives these models access to tools which they can [...]
---
Outline:
(00:55) What are language model agents
(01:36) Overview
(03:31) AgentHarm Benchmark
(05:27) Refusal-Trained LLMs Are Easily Jailbroken as Browser Agents
(06:47) Applying Refusal-Vector Ablation to Llama 3.1 70B Agents
(08:23) Discussion
---
First published:
November 3rd, 2024
Source:
https://www.lesswrong.com/posts/ZoFxTqWRBkyanonyb/current-safety-training-techniques-do-not-fully-transfer-to
---
Narrated by TYPE III AUDIO.
---
…
continue reading
Here are the three papers:
- AgentHarm: A Benchmark for Measuring Harmfulness of LLM Agents
- Refusal-Trained LLMs Are Easily Jailbroken As Browser Agents
- Applying Refusal-Vector Ablation to Llama 3.1 70B Agents
Language model agents are a combination of a language model and a scaffolding software. Regular language models are typically limited to being chat bots, i.e. they receive messages and reply to them. However, scaffolding gives these models access to tools which they can [...]
---
Outline:
(00:55) What are language model agents
(01:36) Overview
(03:31) AgentHarm Benchmark
(05:27) Refusal-Trained LLMs Are Easily Jailbroken as Browser Agents
(06:47) Applying Refusal-Vector Ablation to Llama 3.1 70B Agents
(08:23) Discussion
---
First published:
November 3rd, 2024
Source:
https://www.lesswrong.com/posts/ZoFxTqWRBkyanonyb/current-safety-training-techniques-do-not-fully-transfer-to
---
Narrated by TYPE III AUDIO.
---
Images from the article:
 Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.490 episod
















))